2021年11月29日星期一下午13:30,教育部语言文字应用研究所研究员,博士生导师冯志伟教授做客上海财经大学外国语学院“跨学科语言学研究系列报告”。冯志伟教授为线上会议近两百人带来了一场精彩纷呈的讲座——“机器翻译及其四种类型”。本场讲座是外院校庆学术报告语言学系列报告之一,由李金满教授主持。

冯教授以“巴别塔”传说引入,语言不通而事不就,充分展现了翻译的重要性。随着互联网普及,大数据时代到来,数据信息多以语言文字承载,因此多语翻译的科技需求极大增长,机器翻译技术MT & AI亟待发展。
紧接着,冯教授介绍自然语言处理(Natural Language Processing)一方面可以用于机器翻译,另一方面是智能对话系统,如检索,情感分析,文章自动生成。机器翻译历史最早可追溯至1900年,后来苏联Troyanskii利用制作四种语言的卡片,创造性实现利用机器翻译。1956年Dartmouth Meeting上,十位年轻科学家从学术角度讨论并提出人工智能(Artificial Intelligence),两年前提出的机器翻译便是其中语言智能的一部分。
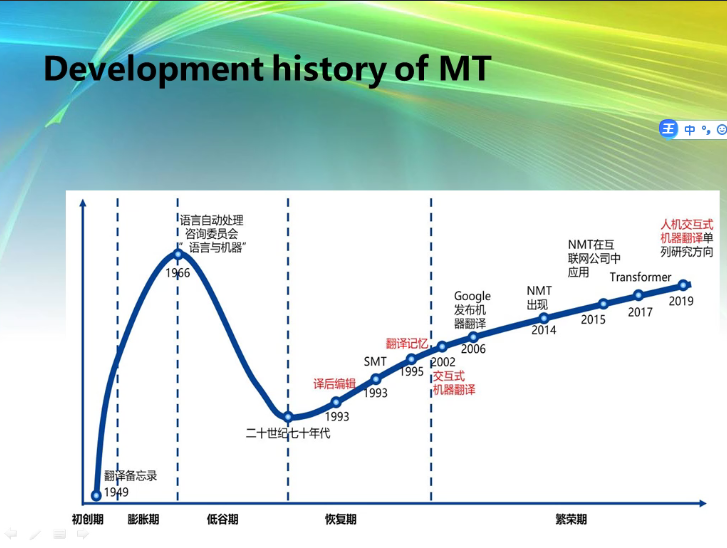
其后,冯教授按照时间发展顺序分别介绍了机器翻译的四种类型:基于规则的机器翻译(Rule-Based Machine Translation),基于实例的机器翻译(Example-Based Machine Translation), 统计机器翻译(Statistical Machine Translation),神经机器翻译(Neural Machine Translation)。冯教授首先概述了四种类型机器翻译的发展历史,并逐一详细讲解各类机器翻译的语言学与统计学理论、计算机知识、运作机制,应用前景。讲解过程中,冯教授时常穿插自身经历,让听众更深刻地理解艰涩难懂的理论知识。比如,讲解基于规则的机器翻译时,冯教授再现了自己开展机器翻译FAJRA(汉-法/英/日/俄/德翻译机)系统研究的过程。讲解基于实例的机器翻译时,冯教授提到他曾利用十几段语料,翻译一段完全不知道的语言,说明翻译本质上是解码与编码的过程。最后,冯教授指出目前机器翻译尚有未处理完善之处,如一词多义、模棱两可、句子省略、未知名词等问题。

“我们一起攀登,直到我透过一个圆洞,看见些美丽的东西显现在苍穹。我们于是走出这里,重见满天繁星。”冯志伟教授引用但丁的《神曲·地狱篇》,指明我们目前可能还在机器翻译探索的圆洞中,只有走出去,才能看到漫天繁星。
冯志伟教授的学术讲座脉络清晰,衔接连贯,例证详实,对机器翻译如数家珍却虚怀若谷。内容干货满满,语言丰富多样,知识博采众长,让听众大开眼界,叹为观止。他不仅给我们梳理了机器翻译的历史,阐明了目前大规模使用的机器翻译背后原理,还为我们指出了机器翻译发展的最新进展,指出了语言学学习者或从业者如何更好与机器翻译结合来适应大数据时代。
供稿:张婷玉(学)
审校:张思佳